“Start Left” versus “Shift Left” – 5 Lessons Based on Real-Life DevOps Horror Stories
by Torsten Volk, Managing Research Director, Hybrid Cloud, Software Defined Infrastructure and Machine Learning
Automation and integration gaps are the DevOps equivalent of small Lego pieces that kids like to strategically place on the floor for us to step on, preferably barefoot. They may look harmless during daylight, but they will inflict an incredible amount of pain when we let down our guard for a moment and walk down the stairs in the dark, just to get a glass of milk or check if we locked the back door.
EMA Cloud Rant with Morpheus Data about the importance of closing cloud automation gaps
“Start left” provides a policy-driven automation and orchestration framework that plugs the gaps of the traditional “shift left” approach by providing developers and operators with a universal access layer to all levels of the application stack. “Start left” does not take away developer or operator tools, but wraps them into a universal management layer, out of band where possible, to enable the overall organization to implement, report on, and ultimately enforce policies. This is the equivalent of equipping parents with a phone app that automatically keeps track of the inevitable Lego traps and sounds a warning signal when they come too close to one of these health hazards.
EMA Cloud Rant with IBM about the importance of starting left
This chart shows a complete inventory of all 8 categories and 27 subcategories of cloud-native development and operations platforms that are currently part of the Cloud-Native Computing Foundation (CNCF). The complexity of this chart shows that a proactive and automated approach toward security, performance, cost control, and availability is mandatory, since continuously verifying the compliant operation of each technology will ultimately drain the organization’s development and operations resources alike.
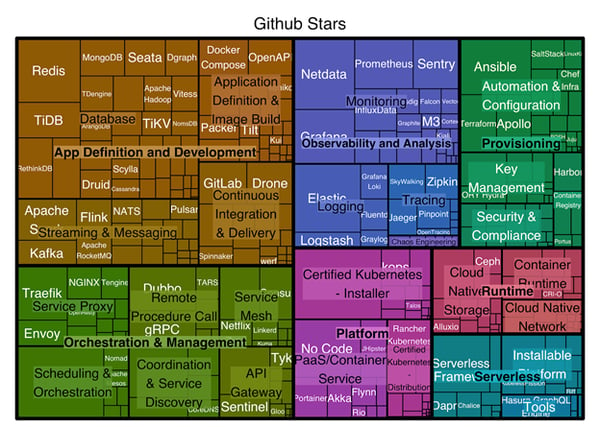
The chart shows the CNCF landscape with the individual products grouped and colored by category and sized by the total number of GitHub stars received (source: EMA).
The following 5 lessons are based on real-life events to provide a clear understanding of the importance of transitioning to a “start left” for DevOps.
Lesson #1: Expect Human Error and Software Bugs
Gradually moving toward a microservices architecture opens the door for a variety of insidious performance issues, service failures, and compliance violations. “We simply did not implement all of the relevant Kubernetes policy controls that would have been needed to prevent the accidental networking configuration mistake that ultimately led to the exposure of critical customer records,” said a DevOps lead at a major multinational retail chain. Due to the dynamic nature of container networking and the many dependencies between the container networking interface and the operating system, this type of potentially catastrophic event can occur through a simple human error or it could be caused by a software bug at the container, VM, operating system, or network level.
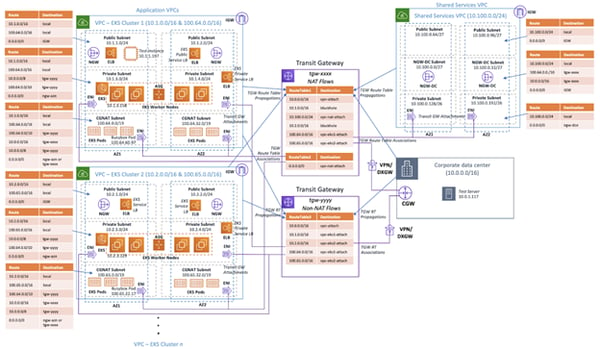
The chart shows the complexity of traffic routing within Amazon’s managed Kubernetes environment. Mistakes in any of these routing tables can lead to performance problems, downtime, or even exposing sensitive data to the wrong audience (source: AWS).
Lesson #2: Never Trick Policy Frameworks
“We thought we had found the ideal workaround for a known performance problem when the Kubernetes scheduler created significant application latency by denying CPU requests, seemingly without any valid reason. Turning off CPU throttling unleashed the full power of our host CPUs, instantly cutting application latency in half,” explained a DevOps engineer at an online travel booking platform. But a few weeks later, during a traffic spike, this workaround caused a dramatic chain reaction of node after node freezing due to Kubernetes no longer having the option to throttle traffic to protect its own core services. “By turning off dynamic throttling, we had created a dangerous Easter egg that added significant operational risk and ultimately led to application downtime of several hours.”

The chart shows an example of how we inform Kubernetes about storage requirements and priorities of our applications. If we ignore or code around these policy definitions, we risk problems down the road because the scheduler becomes now blind to at least part of the application’s runtime requirements (source: Kubernetes.io).
Lesson #3: Managed Cloud Services are not a Life Insurance
Amazon EKS, Azure AKS, and Google GKE all are good solutions to consume Kubernetes resources while offloading some of the deployment and management efforts to the hyperscalers. “The situation started heating up when our applications showed seemingly random intermittent latency spikes. We immediately started iterating through a series of load testing scenarios, but struck out entirely when it came to identifying the problem pattern. It seemed unlikely for EKS to be the culprit, since Amazon was not aware of any container networking problems on their end," says a software developer for a major Indian IT services outsourcer. In the end, the problem turned out to be an integration issue between a microservice running on Amazon’s EC2 platform and a specific container image running on EKS.
.png?width=600&name=how%20Amazon%E2%80%99s%20managed%20Kubernetes%20service%20(EKS).png)
The chart shows how Amazon’s managed Kubernetes service (EKS) still needs integration with the rest of the AWS universe. Each integration point brings a certain operational risk for Kubernetes applications (source: AWS).
Lesson #4: Blueprints Need to be Part of GitOps
“Having used Terraform across our organization for years, I can tell you that there is no such thing as infrastructure-independent application blueprints. The manual effort involved in continuously maintaining different sets of configuration parameters for different clouds makes no business sense,” said the VP of Corporate Cloud Operations of a major German online portal. “Our main challenge now is to keep all of the different blueprints under central control, centrally updated, and audit-ready. We are simply missing a unified control center where we can specify, code, and observe compliance controls across data center, AWS, Google Cloud, Azure, and any potential future deployment option.” This quote exactly describes the key requirement for “starting left,” which is: to be able to centrally manage and control applications throughout their lifecycle, we need one central repository storing all application and infrastructure code, without exception.

This brilliant single chart explanation of GitOps captures the importance of having all application and infrastructure code in one place (source: @luisfaceira).
Lesson #5: Backup and Restore Need a Refresh
“We found out the hard way that backing up entire application environments has become tricky when microservices and traditional enterprise applications are mixed together. At first, when we restored the quality control application for our CNC machines, we thought we were in the clear. However, then it turned out that there were seemingly inexplicable errors in the control data. Eventually, we found that these errors were due to one of our microservices dumping operations parameters to a local drive that was not part of the backup routine,” explained a software engineer at a metal parts manufacturer. This example illustrates that the traditional backup approach needs to be replaced with a new application-centric paradigm, where coding around backup coverage is no longer possible.